
Homepage
Biography
I graduated from Northwestern Polytechnical University (Xi’an) with a bachelor's degree in Electric Engineering in 2012 and from Peking University (Beijing) with a doctoral degree in Microelectronics in 2018. After that, I joined the Institute of Computing Technology, Chinese Academy of Sciences in 2018 and was promoted to associate professor in 2021. With more than ten years of experience in Electric Engineering, now I’m doing research in the field of computer architecture, which is a thriving field aiming to make better use of electric devices and circuits. I have experiences in making various prototypes such as a Monte Carlo device simulator, an Open-Accelerator-Module-based Compute-in-Memory server system, an edge AI computing system and so on. My research interest includes disaggregated memory system, binary translation for heterogenerous computing and LLM edge computing system.
Research Interest
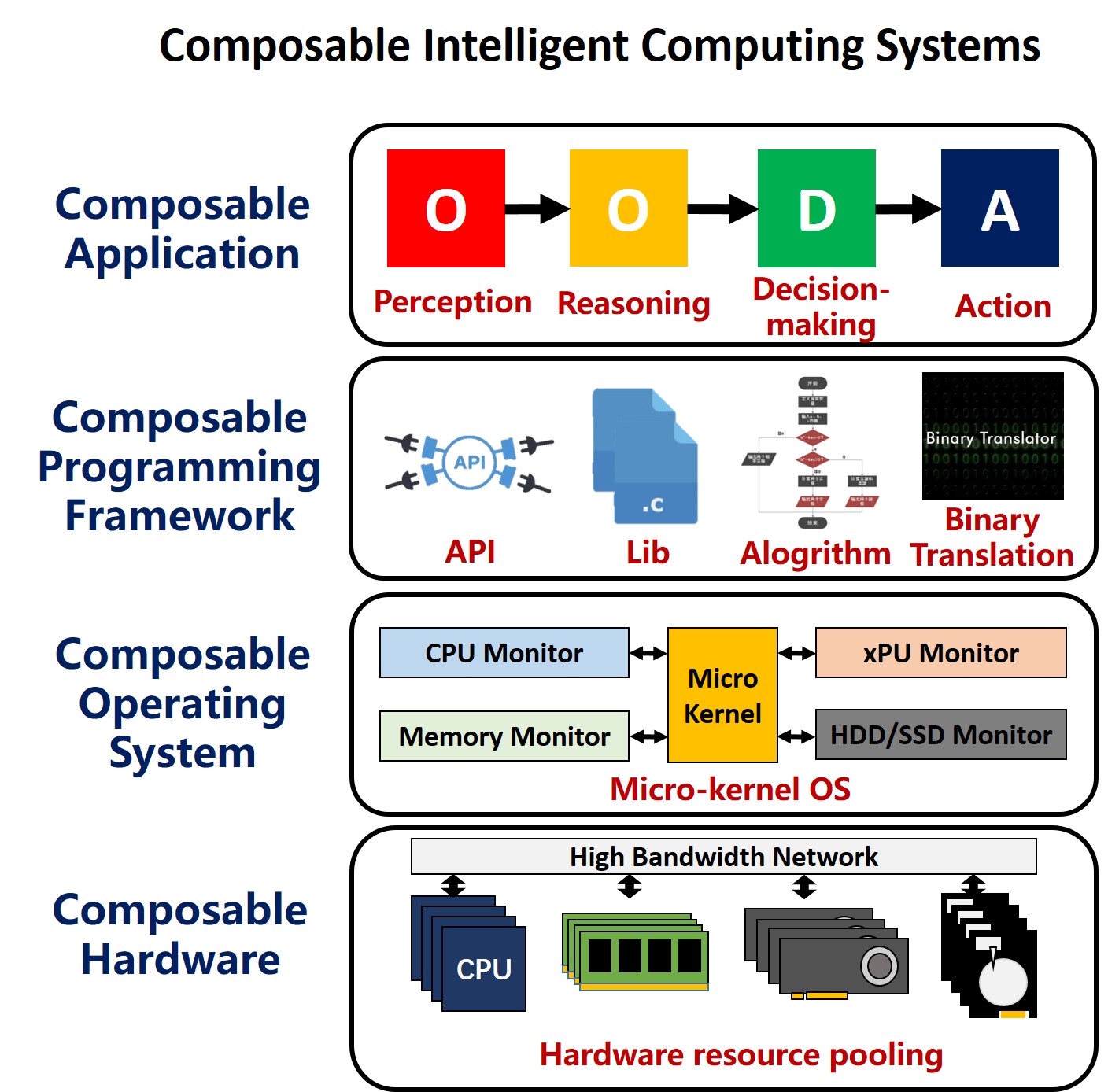
- Disaggregated memory system
Distributed memory is considered a cornerstone technology for next-generation cloud data centers, and is expected to completely solve the "memory wall" problem. In this technology, an independent, scalable memory resource pool in computing systems is formed by decoupling memory resources tightly coupled to computing units such as CPU. This memory resource pool provides on-demand, transparent memory access capabilities to all compute units via high-speed networks such as Remote Direct Memory Access (RDMA)、Peripheral Component Interconnect Express(PCIe)、Compute Express Link(CXL)and so on. In this scenario, compute nodes no longer monopolize their local memories but can access arbitrary memory resources through the network/interconnect with low latency, which just as if it were local memory. This will enable global sharing and flexible scheduling of memory resources and make computing system upgrading more effective. However, there are also significant challenges that need to be overcome. Network/Interconnect transmission latency is significantly higher than local memory access. This requires complex system software and runtime support to eliminate the impact. What’s more,the resource management and scheduling are more complex in disaggregate memory systems than traditional computing systems, requiring efficient handling of issues such as global memory allocation, data consistency, fault tolerance, and fault isolation.
- Binary translation for heterogenerous computing
Binary translation for heterogeneous computing is a valuable technology that allows legacy applications written for general-purpose CPUs to transparently leverage the massive parallel computing capabilities of accelerators without acquiring source codes and tedious manual rewriting and translating, resulting in significant performance improvements, which is important in closed-source application areas. It aims to automatically identify and extract parallelizable, compute-intensive code segments (such as loops and matrix operations) embedded in traditional CPU binary programs, dynamically translate these segments, and effectively offload them to specialized hardware accelerators (such as GPGPUs, FPGAs, and NPUs). There are also many major challenges here. First, the code identification and extraction challenge. Accurately identifying code regions with data-parallel characteristics or specific computational patterns from the sequential CPU code and safely isolating them is not easy. Second, the parallelization and mapping challenges. Automatically paralleling sequential codes and efficiently mapping them to the parallel execution model of hardware accelerators while correctly handling issues such as data dependencies and branch divergence is remaining an open problem. Third, the data management and transfer overhead. How to minimize the data transfer overhead between the CPU and accelerator? Without effective analysis, transfer latency could completely offset or even exceed the gains in computational acceleration. Finally, the programming model differences. There is a significant gap between the shared memory and pointer model of the CPU and the hierarchical memory and explicit data transfer model of accelerators, making automatic and correct conversion extremely complex.
- LLM edge computing system
LLM edge computing system design needs to deal with the problem deploying and running LLM models in resource-constrained edge environments. It aims to achieve efficient, low-latency, secure, and reliable model inference (sometimes including lightweight training) within the constraints of limited computing power, memory, power consumption, and network bandwidth, which allows intelligence to be truly decentralized to the source of data and meets the critical requirements of real-time response, and bandwidth conservation and private protection. This field faces significant challenges, centered on the significant conflict between model size and resource constraints. Large models with billions or even tens of billions of parameters require several to tens of GB of memory for their weights alone, far exceeding the capacity of most edge devices. The generative inference computational complexity of large models is enormous, and the limited computing power of edge device processors makes it difficult to meet real-time requirements. Edge devices are typically battery-powered, and the intensive computation of large models can dramatically reduce device battery life, placing extremely high demands on computational energy efficiency (TOPS/W). Unstable network connections and the need to cope with diverse hardware platforms and input data place high demands on system adaptability and robustness.